二部图(二分图)
什么是二分图
对于一个无向图G=(V,E),如果将顶点V分隔为两个互不相交的子集(A,B),且图中的每条边(i,j)所关联的两个顶点分别属于两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
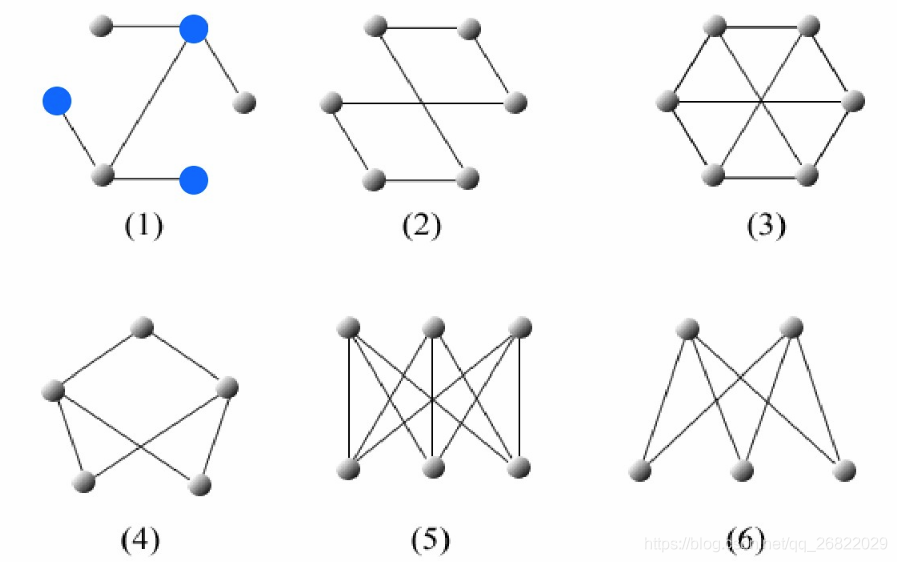
二分图有一个重要的性质,即图中不含奇数环,这是二分图成立的充要条件。
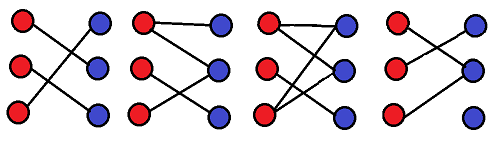
二分图不一定是连通图。
染色法判断二分图
判断一个无向图是否是二分图,通常使用染色法。
染色法的实现思路(DFS):
1.用1,2代表两个颜色,0代表未染色,任选一个点染成1或2
2.遍历所有点,每次将未染色的点进行dfs
3.若染色失败即break/return
#include <bits/stdc++.h>
using namespace std;
const int N = 100010, M = 200010;
int n, m;
int h[N], e[M], ne[M], idx;
int color[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
bool dfs(int u, int c)
{
color[u] = c; // 染色
for (int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
if (!color[j]){
if (!dfs(j, 3 - c)) return false; // 如果在dfs递归的过程中出现染色失败,则整个图都不是二分图
}
else if (color[j] == c) return false; // 如果一条边的两端点同种颜色,则染色失败
}
return true; // 无染色错误则染色成功
}
int main()
{
cin >> n >> m;
memset(h, -1, sizeof h);
while (m -- ){
int a, b;
cin >> a >> b;
add(a, b), add(b, a);
}
bool flag = true;
for (int i = 1; i <= n; i ++ ){ // 遍历所有点,因为二分图不一定是连通图
if (!color[i]){
if (!dfs(i, 1)){
flag = false;
break;
}
}
}
if (flag) printf("Yes\n");
else printf("No");
return 0;
}我在写时遇到一个问题
if (!color[j]){
if (!dfs(j, 3 - c)) return false;为何不能改成
if (!color[j]){
dfs(j, 3 - c);这样改来,我以为在判断该点没有染色的时候,dfs只是为了染色,根本的判断染色失败在下面的一行判断中,所以这样更换没有问题,但实则不然。
这个dfs的作用不只是为了染色,也是利用dfs的返回值,判断在递归过程中是否产生了染色错误。而不加这个判断,只能判断u是否处于奇数环中,而u不一定处于奇数环,所以有可能判断错误。
二分图的最大匹配(匈牙利算法)
匹配:在图论中一个匹配是指一个边的集合,其中任意两条边都没有公共顶点。
最大匹配,一个图所有匹配中,所含匹配边数最多的匹配称为最大匹配。
匈牙利算法的过程
1.从左集合依次找右集合的点,如果有右集合的点还没有被匹配,就把它们连上一条边。
2.如果左集合中某一点找到的右集合中一点已经匹配过,那么就从该右集合点反找它匹配的左集合点,并找该左集合点有没有别的右集合点可以连,如果有,则连接这个右集合点,原右集合点与新左集合点相连。
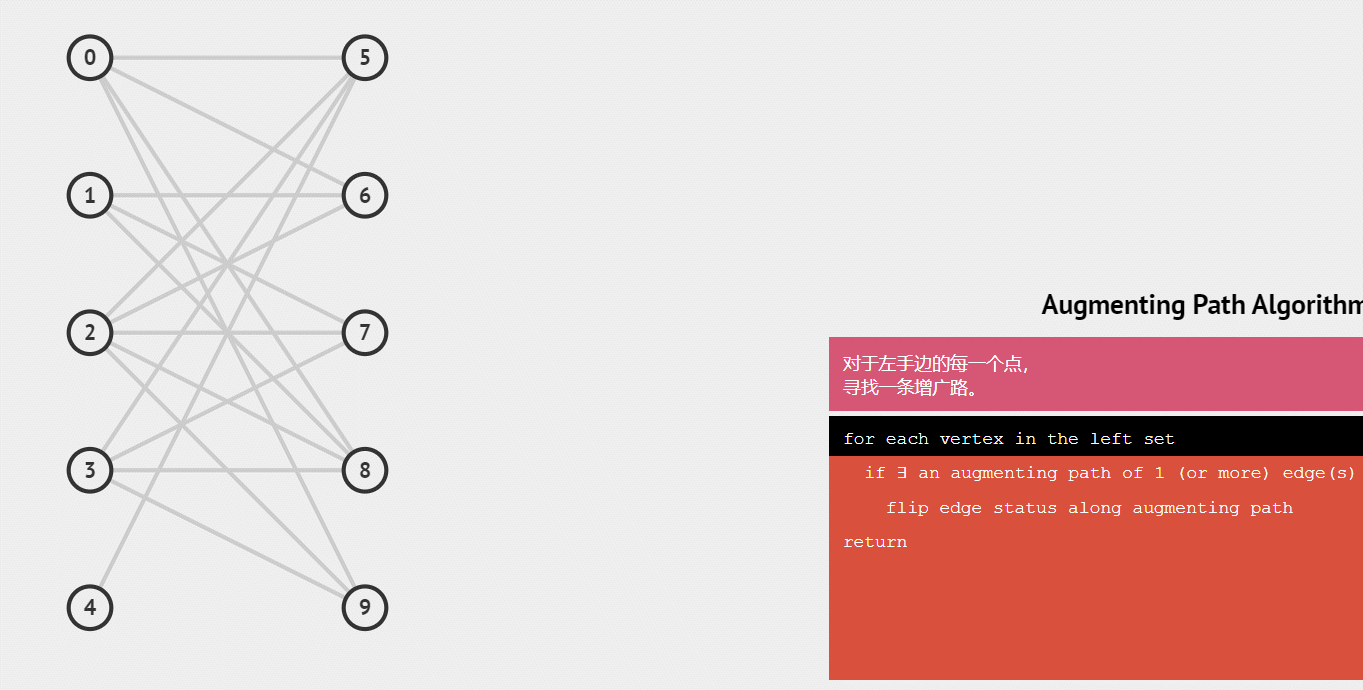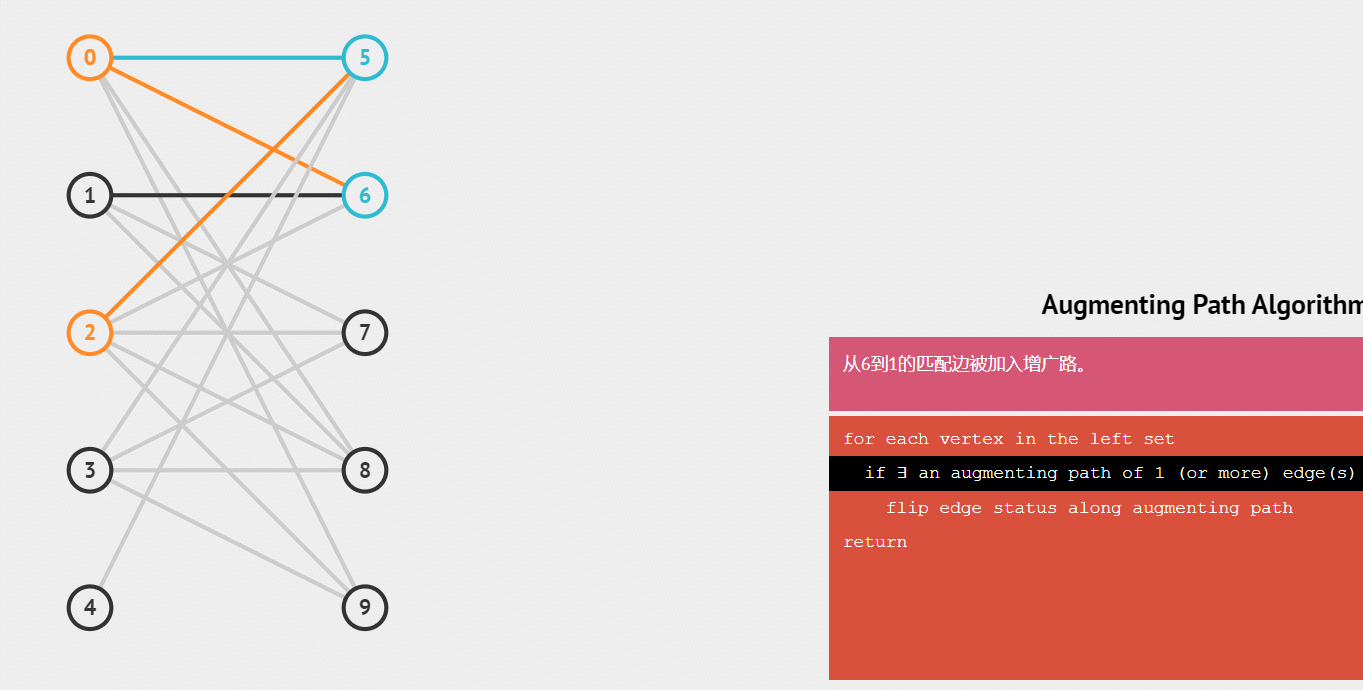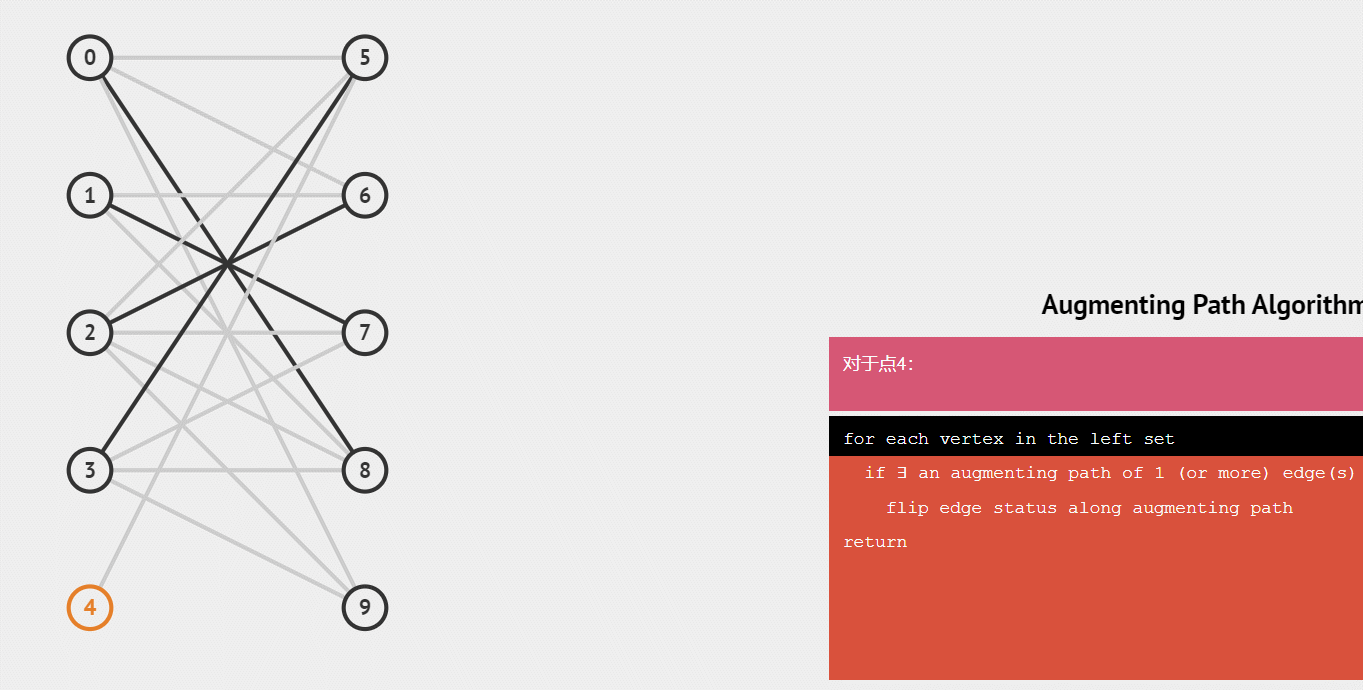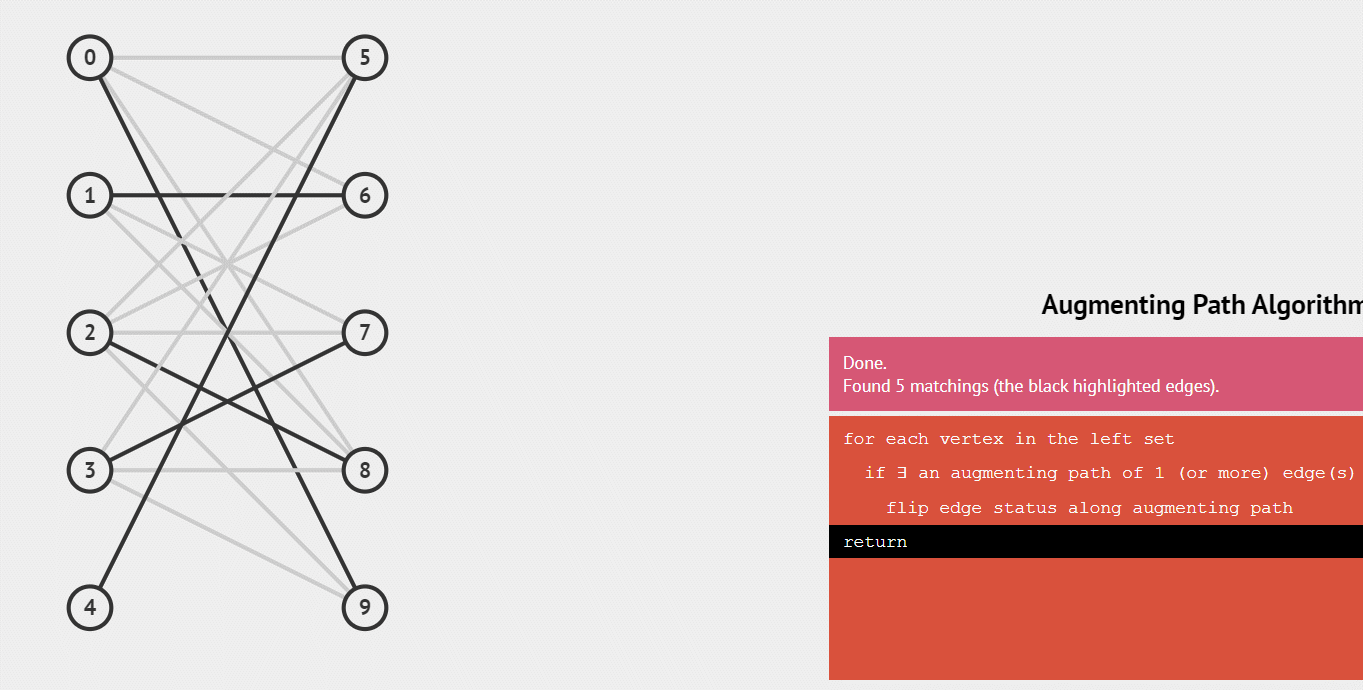
虽然二分图是无向图,但匈牙利算法只需要从左边集合找右边集合,因此我们只存一条边也可以。
#include <bits/stdc++.h>
using namespace std;
const int N = 510, M = 100010;
int n1, n2, m;
int h[N], e[M], ne[M], idx;
int match[N];
bool st[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i]){
int j = e[i];
if (!st[j]){
st[j] = true;
if (match[j] == 0 || find(match[j])){
match[j] = x;
return true;
}
}
}
return false;
}
int main()
{
scanf("%d%d%d", &n1, &n2, &m);
memset(h, -1, sizeof h);
while (m -- ){
int a, b;
cin >> a >> b;
add(a, b);
}
int res = 0;
for (int i = 0; i <= n1; i ++ ){
memset(st, false, sizeof st);
if (find(i)) res ++;
}
cout << res << endl;
return 0;
}为什么要开st数组?为什么要memset?
假设我们找到左1与右1相连,左2也欲与右1相连,于是返回左1再次查找,在查找过程中我们会一直进入find(match[1])的递归过程中。
如果加了st数组呢?在返回左1之前我们就将右1设为true,在返回左1后就不会再判断右1,因为左1已经与右1相连,也即是说,每次返回左边寻找之前都会将这个左点相连的右点设定一次,避免重复查找。而对于不同的左点,每次重新开始找都要初始化一次st数组。



